My research lies at the intersection of
machine learning, computer vision and computer graphics.

|
3D Gaussian Splatting as Markov Chain Monte Carlo
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Weiwei Sun, Jeff Tseng,
Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, Kwang Moo Yi
NeurIPS 2024, Webpage
Abstract
While 3D Gaussian Splatting has recently become popular for
neural rendering, current methods rely on carefully engineered cloning and
splitting strategies for placing Gaussians, which does not always generalize and
may lead to poor-quality renderings. In addition, for real-world scenes, they
rely on a good initial point cloud to perform well. In this work, we rethink 3D
Gaussians as random samples drawn from an underlying probability distribution
describing the physical representation of the scene -- in other words, Markov
Chain Monte Carlo (MCMC) samples. Under this view, we show that the 3D Gaussian
updates are strikingly similar to a Stochastic Langevin Gradient Descent (SGLD)
update. As with MCMC, samples are nothing but past visit locations, adding new
Gaussians under our framework can simply be realized without heuristics as
placing Gaussians at existing Gaussian locations. To encourage using fewer
Gaussians for efficiency, we introduce an L1-regularizer on the Gaussians. On
various standard evaluation scenes, we show that our method provides improved
rendering quality, easy control over the number of Gaussians, and robustness to
initialization.
|

|
Volumetric Rendering with Baked Quadrature Fields
Gopal Sharma, Daniel Rebain, Andrea Tagliasacchi, Kwang Moo Yi.
ECCV 2024, Webpage
Abstract
We propose a novel Neural Radiance Field (NeRF) representation
for non-opaque scenes that allows fast inference by utilizing textured polygons.
Despite the high-quality novel view rendering that NeRF provides, a critical
limitation is that it relies on volume rendering that can be computationally
expensive and does not utilize the advancements in modern graphics hardware.
Existing methods for this problem fall short when it comes to modelling
volumetric effects as they rely purely on surface rendering. We thus propose to
model the scene with polygons, which can then be used to obtain the quadrature
points required to model volumetric effects, and also their opacity and colour
from the texture. To obtain such polygonal mesh, we train a specialized field
whose zero-crossings would correspond to the quadrature points when volume
rendering, and perform marching cubes on this field. We then rasterize the
polygons and utilize the fragment shaders to obtain the final colour image. Our
method allows rendering on various devices and easy integration with existing
graphics frameworks while keeping the benefits of volume rendering alive.
|

|
Unsupervised Keypoints from Pretrained Diffusion Models
Eric Hedlin, Gopal Sharma, Shweta Mahajan, Xingzhe He, Hossam Isack, Abhishek
Kar,
Helge Rhodin, Andrea Tagliasacchi, Kwang Moo Yi.
CVPR 2024, Webpage
Abstract
Unsupervised learning of keypoints and landmarks has seen
significant progress with the help of modern neural network architectures, but
performance is yet to match the supervised counterpart, making their
practicability questionable. We leverage the emergent knowledge within
text-to-image diffusion models, towards more robust unsupervised keypoints. Our
core idea is to find text embeddings that would cause the generative model to
consistently attend to compact regions in images (i.e. keypoints). To do so, we
simply optimize the text embedding such that the cross-attention maps within the
denoising network are localized as Gaussians with small standard deviations. We
validate our performance on multiple dataset: the CelebA, CUB-200-2011,
Tai-Chi-HD, DeepFashion, and Human3.6m datasets. We achieve significantly
improved accuracy, sometimes even outperforming supervised ones, particularly
for data that is non-aligned and less curated.
|

|
PointNeRF++: A multi-scale, point-based Neural Radiance Field
Weiwei Sun, Eduard Trulls, Yang-Che Tseng, Sneha Sambandam, Gopal Sharma,
Andrea Tagliasacchi, Kwang Moo Yi.
ECCV 2024, Webpage
Abstract
Point clouds offer an attractive source of information to
complement images in neural scene representations, especially when few images
are available. Neural rendering methods based on point clouds do exist, but they
do not perform well when the point cloud quality is low---e.g., sparse or
incomplete, which is often the case with real-world data. We overcome these
problems with a simple representation that aggregates point clouds at multiple
scale levels with sparse voxel grids at different resolutions. To deal with
point cloud sparsity, we average across multiple scale levels---but only among
those that are valid, i.e., that have enough neighboring points in proximity to
the ray of a pixel. To help model areas without points, we add a global voxel at
the coarsest scale, thus unifying ``classical'' and point-based NeRF
formulations.
|
|
Accelerating Neural Field Training via Soft Mining
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Hossam Isack, Abhishek Kar
Andrea Tagliasacchi, Kwang Moo Yi
CVPR 2024, Webpage
Abstract
We present an approach to accelerate Neural Field training by
efficiently selecting sampling locations. While Neural Fields have recently
become popular, it is often trained by uniformly sampling the training domain,
or through handcrafted heuristics. We show that improved convergence and final
training quality can be achieved by a soft mining technique based on importance
sampling: rather than either considering or ignoring a pixel completely, we
weigh the corresponding loss by a scalar. To implement our idea we use Langevin
Monte-Carlo sampling. We show that by doing so, regions with higher error are
being selected more frequently, leading to more than 2x improvement in
convergence speed.
|
|
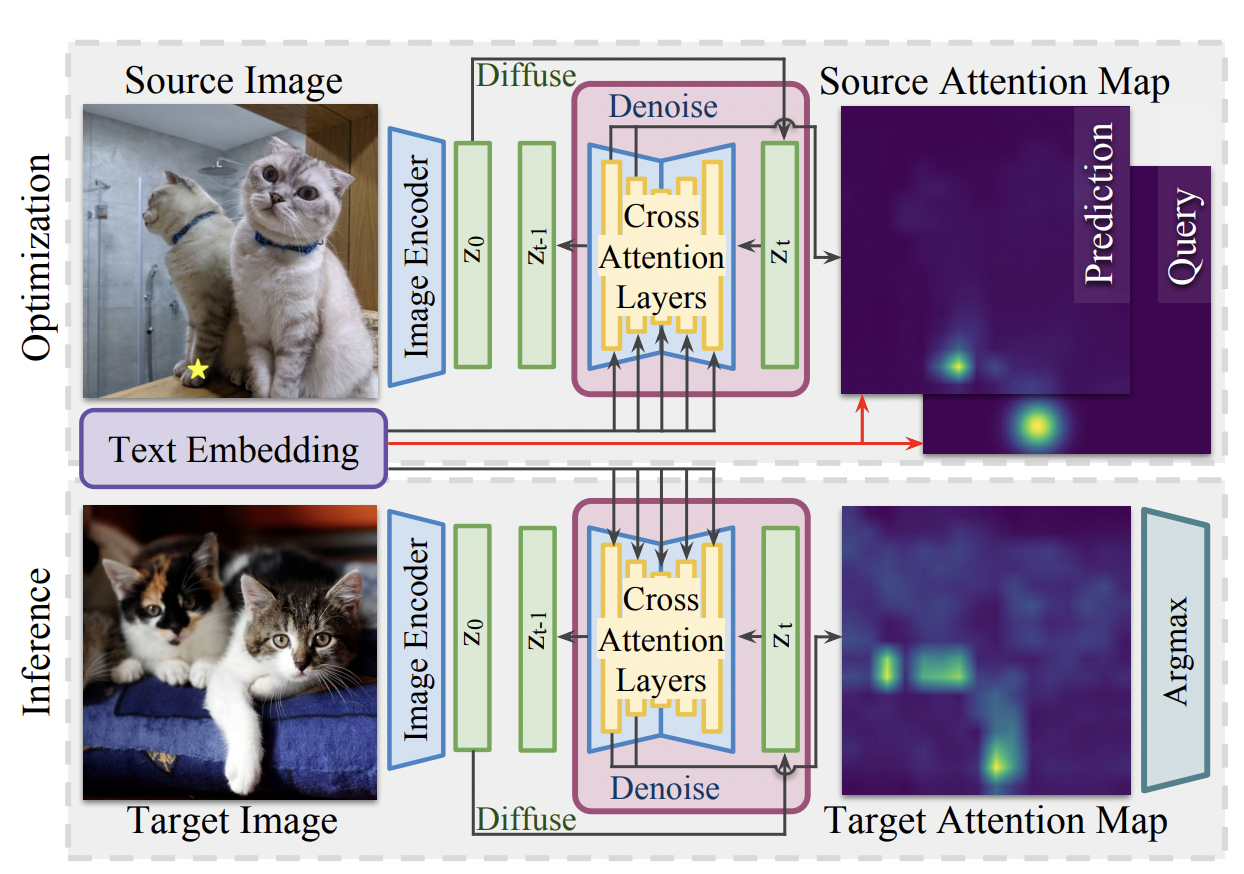
Unsupervised Semantic Correspondence Using Stable Diffusion
Eric Hedlin, Gopal Sharma, Shweta Mahajan, Hossam Isack, Abhishek Kar, Andrea
Tagliasacchi, Kwang Moo Yi.
NeurIPS 2023, Webpage
Abstract
Text-to-image diffusion models are now capable of generating
images that are often indistinguishable from real images. To generate such
images, these models must understand the semantics of the objects they are asked
to generate. In this work we show that, without any training, one can leverage
this semantic knowledge within diffusion models to find semantic correspondences
-- locations in multiple images that have the same semantic meaning.
Specifically, given an image, we optimize the prompt embeddings of these models
for maximum attention on the regions of interest. These optimized embeddings
capture semantic information about the location, which can then be transferred
to another image. By doing so we obtain results on par with the strongly
supervised state of the art on the PF-Willow dataset and significantly
outperform (20.9% relative for the SPair-71k dataset) any existing weakly or
unsupervised method on PF-Willow, CUB-200 and SPair-71k datasets.
|
|
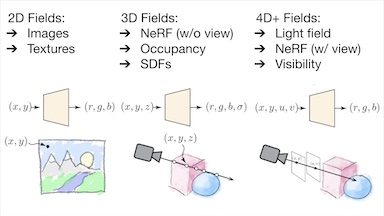
Attention Beats Concatenation for Conditioning Neural Fields
Daniel Rebain, Mark J. Matthews, Kwang Moo Yi, Gopal Sharma, Dmitry Lagun,
Andrea Tagliasacchi
TMLR 2023,
Abstract
Neural fields model signals by mapping coordinate inputs to sampled values. They
are becoming an increasingly important backbone architecture across many fields
from vision and graphics to biology and astronomy. In this paper, we explore the
differences between common conditioning mechanisms within these networks, an
essential ingredient in shifting neural fields from memorization of signals to
generalization, where the set of signals lying on a manifold is modelled
jointly. In particular, we are interested in the scaling behaviour of these
mechanisms to increasingly high-dimensional conditioning variables. As we show
in our experiments, high-dimensional conditioning is key to modelling complex
data distributions, thus it is important to determine what architecture choices
best enable this when working on such problems. To this end, we run experiments
modelling 2D, 3D, and 4D signals with neural fields, employing concatenation,
hyper-network, and attention-based conditioning strategies -- a necessary but
laborious effort that has not been performed in the literature. We find that
attention-based conditioning outperforms other approaches in a variety of
settings.
|
|
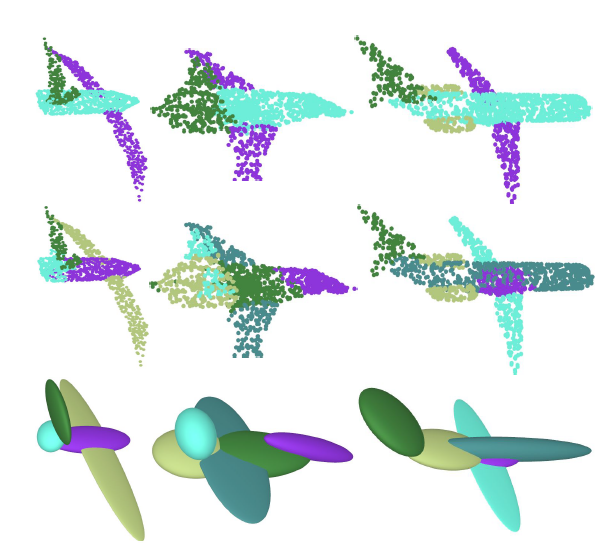
PRIFIT: Learning to Fit Primitives Improves Few Shot Point Cloud Segmentation
Gopal Sharma*, Bidya Dash*, Matheus Gadelha, Aruni
RoyChowdhury, Marios Loizou, Evangelos Kalogerakis, Liangliang Cao, Erik
Learned-Miller, Rui Wang and Subhransu Maji.
SGP 2022, Webpage
Abstract
We present PriFit, a simple approach for label efficient learning
of 3D shape segmentation networks. PriFit is based on a self-supervised task of
decomposing the surface of a 3D shape into geometric primitives.
It can be readily applied to existing network architectures for 3D shape
segmentation,
and improves their performance in the few-shot setting, as we demonstrate in the
widely used ShapeNet and PartNet benchmarks.
PriFit outperforms the prior state-of-the-art in this setting, suggesting that
decomposability into primitives is a useful prior for learning representations
predictive of semantic parts.
We present a number of experiments varying the choice of geometric primitives
and downstream tasks to demonstrate the effectiveness of the method.
|
|
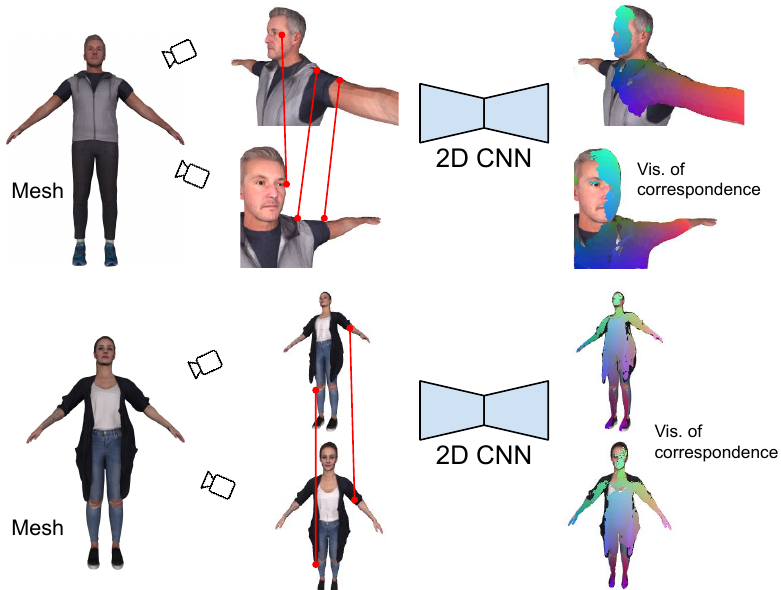
MvDeCor: Multi-view Dense Correspondence Learning for Fine-grained 3D
Segmentation
Gopal Sharma, Kangxue Yin, Subhransu Maji, Evangelos Kalogerakis, Or Litany,
and Sanja Fidler
ECCV 2022, Webpage
Abstract
We propose to utilize self-supervised techniques in the 2D domain for
fine-grained 3D shape segmentation tasks. This is inspired by the
observation that view-based surface representations are more effective
at modeling high-resolution surface details and texture than their 3D
counterparts based on point clouds or voxel occupancy. Specifically,
given a 3D shape, we render it from multiple views, and set up a dense
correspondence learning task within the contrastive learning
framework. As a result, the learned 2D representations are
view-invariant and geometrically consistent, leading to better
generalization when trained on a limited number of labeled shapes than
alternatives based on self-supervision in 2D or 3D alone. Experiments
on textured (RenderPeople) and untextured (PartNet) 3D datasets show
that our method outperforms state-of-the-art alternatives in
fine-grained part segmentation. The improvements over baselines are
greater when only a sparse set of views is available for training or
when shapes are textured, indicating that MvDeCor benefits from both 2D
processing and 3D geometric reasoning.
|
|
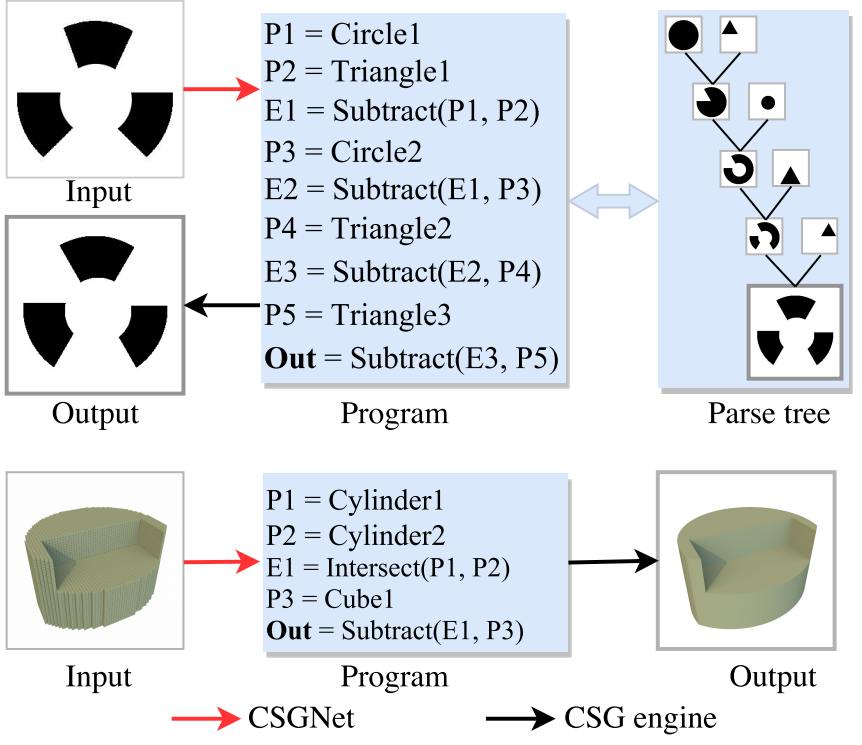
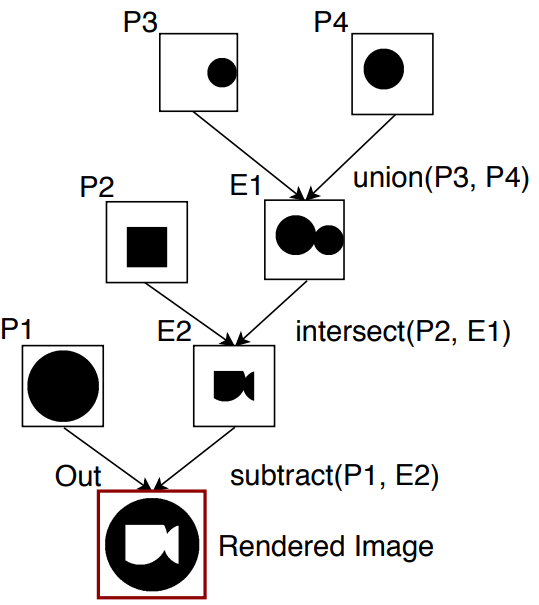
Neural Shape Parsers for Constructive Solid Geometry
Gopal Sharma, Rishabh Goyal, Difan Goyal, Evangelos Kalogerakis and Subhransu
Maji
TPAMI, Paper
Abstract
Constructive Solid Geometry (CSG) is a geometric modeling
technique that defines complex shapes by recursively applying boolean operations
on primitives such as spheres and cylinders. We present CSGNet, a deep network
architecture that takes as input a 2D or 3D shape and outputs a CSG program that
models it. Parsing shapes into CSG programs is desirable as it yields a compact
and interpretable generative model. However, the task is challenging since the
space of primitives and their combinations can be prohibitively large. CSGNet
uses a convolutional encoder and recurrent decoder based on deep networks to map
shapes to modeling instructions in a feed-forward manner and is significantly
faster than bottom-up approaches. We investigate two architectures for this task
— a vanilla encoder (CNN) - decoder (RNN) and another architecture that augments
the encoder with an explicit memory module based on the program execution stack.
The stack augmentation improves the reconstruction quality of the generated
shape and learning efficiency. Our approach is also more effective as a shape
primitive detector compared to a state-of-the-art object detector. Finally, we
demonstrate CSGNet can be trained on novel datasets without program annotations
through policy gradient techniques.
Cite
@ARTICLE{9293398,
author={G. {Sharma} and R. {Goyal} and D. {Liu} and E. {Kalogerakis} and S.
{Maji}},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Neural Shape Parsers for Constructive Solid Geometry},
year={2020},
volume={},
number={},
pages={1-1},
doi={10.1109/TPAMI.2020.3044749}}
|
|
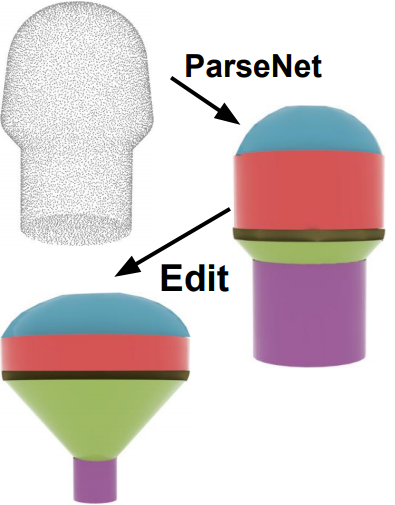
ParSeNet: A Parametric Surface Fitting Network for 3D Point Clouds
Gopal Sharma ,
Difan Liu,
Evangelos Kalogerakis,
Subhransu Maji,
Siddhartha Chaudhuri and
Radomír Měch
ECCV 2020, Paper
Abstract
We propose a novel, end-to-end trainable, deep network called ParSeNet that
decomposes a 3D point cloud into parametric surface patches, including B-spline
patches as well as basic geometric primitives. ParSeNet is trained on a
large-scale dataset of man-made 3D shapes and captures high-level semantic
priors for shape decomposition. It handles a much richer class of primitives
than prior work, and allows us to represent surfaces with higher fidelity. It
also produces repeatable and robust parametrizations of a surface compared to
purely geometric approaches. We present extensive experiments to validate our
approach against analytical and learning-based alternatives.
Cite
@misc{sharma2020parsenet,
title={ParSeNet: A Parametric Surface Fitting Network for 3D Point Clouds},
author={Gopal Sharma and Difan Liu and Evangelos Kalogerakis and Subhransu Maji
and Siddhartha Chaudhuri and Radomír Měch},
year={2020},
eprint={2003.12181},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
|
Label-Efficient Learning on Point Clouds using Approximate Convex
Decompositions
Matheus Gadelha*, Aruni RoyChowdhury*, Gopal Sharma ,
Evangelos Kalogerakis, Liangliang Cao, Erik Learned-Miller, Rui Wang, Subhransu Maji
ECCV 2020, Paper
Abstract
The problems of shape classification and part segmentation from 3D point clouds
have garnered increasing attention in the last few years. But both of these
problems suffer from relatively small training sets, creating the need for
statistically efficient methods to learn 3D shape representations. In this work,
we investigate the use of Approximate Convex Decompositions (ACD) as a
self-supervisory signal for label-efficient learning of point cloud
representations. Decomposing a 3D shape into simpler constituent parts or
primitives is a fundamental problem in geometrical shape processing. There has
been extensive work on such decompositions, where the criterion for simplicity
of a constituent shape is often defined in terms of convexity for solid
primitives. In this paper, we show that using the results of ACD to approximate
a ground truth segmentation provides excellent self-supervision for learning 3D
point cloud representations that are highly effective on downstream tasks. We
report improvements over the state-of-theart in unsupervised representation
learning on the ModelNet40 shape classification dataset and significant gains in
few-shot part segmentation on the ShapeNetPart dataset.
Cite
@misc{gadelha2020labelefficient,
title={Label-Efficient Learning on Point Clouds using Approximate Convex
Decompositions},
author={Matheus Gadelha and Aruni RoyChowdhury and Gopal Sharma and Evangelos
Kalogerakis and Liangliang Cao and Erik Learned-Miller and Rui Wang and
Subhransu Maji},
year={2020},
eprint={2003.13834},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
|
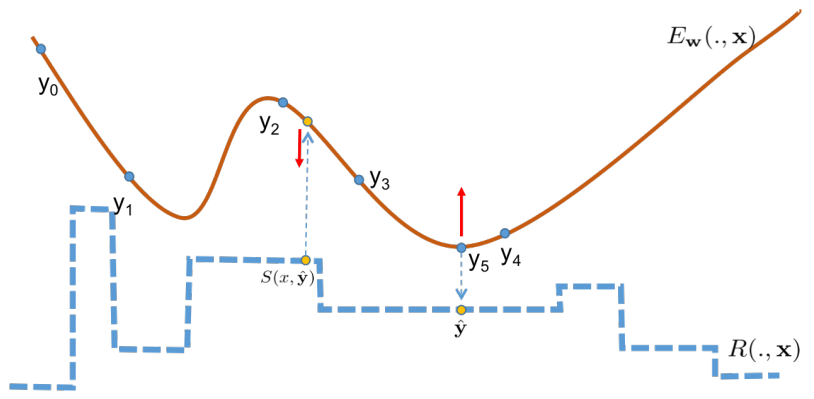
Search-Guided, Lightly-supervised Training of Structured Prediction Energy
Networks
Amirmohammad Rooshenas, Dongxu Zhang, Gopal Sharma, and Andrew McCallum
NeurIPS 2019, Paper
Abstract
In structured output prediction tasks, labeling ground-truth training output is
often expensive. However, for many tasks, even when the true output is unknown,
we can evaluate predictions using a scalar reward function, which may be easily
assembled from human knowledge or non-differentiable pipelines. But searching
through the entire output space to find the best output with respect to this
reward function is typically intractable. In this paper, we instead use
efficient truncated randomized search in this reward function to train
structured prediction energy networks (SPENs), which provide efficient test-time
inference using gradient-based search on a smooth, learned representation of the
score landscape, and have previously yielded state-of-the-art results in
structured prediction. In particular, this truncated randomized search in the
reward function yields previously unknown local improvements, providing
effective supervision to SPENs, avoiding their traditional need for labeled
training data.
Cite
@incollection{NIPS2019_9507,
title = {Search-Guided, Lightly-Supervised Training of Structured Prediction
Energy Networks},
author = {Rooshenas, Amirmohammad and Zhang, Dongxu and Sharma, Gopal and
McCallum, Andrew},
booktitle = {Advances in Neural Information Processing Systems 32},
editor = {H. Wallach and H. Larochelle and A. Beygelzimer and F.
d\textquotesingle Alch\'{e}-Buc and E. Fox and R. Garnett},
pages = {13522--13532},
year = {2019},
publisher = {Curran Associates, Inc.},
url =
{http://papers.nips.cc/paper/9507-search-guided-lightly-supervised-training-of-structured-prediction-energy-networks.pdf}
}
|
|
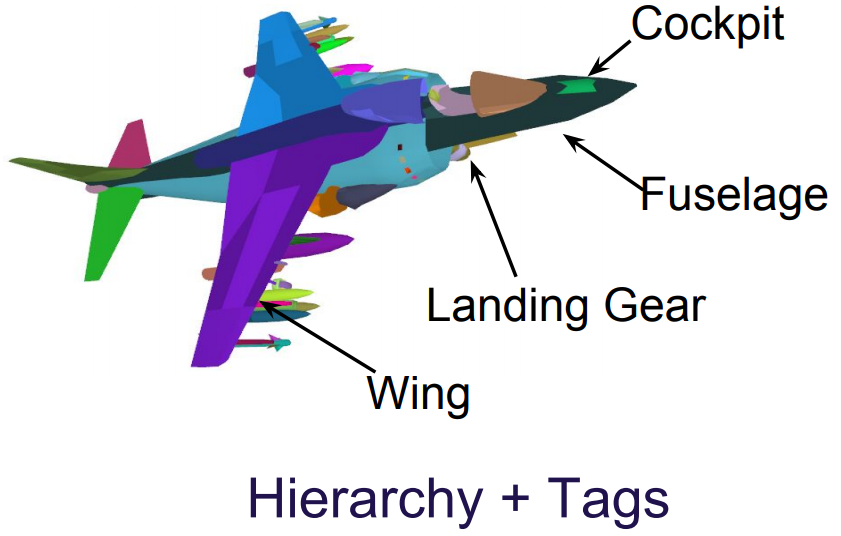
Learning Point Embeddings from Shape Repositories for Few-Shot Segmentation
Gopal Sharma, Evangelos Kalogerakis and Subhransu Maji.
3DV 2019, Paper
Abstract
User generated 3D shapes in online repositories contain rich information about
surfaces, primitives, and their geometric relations, often arranged in a
hierarchy. We present a framework for learning representations of 3D shapes that
reflect the information present in this meta data and show that it leads to
improved generalization for semantic segmentation tasks. Our approach is a point
embedding network that generates a vectorial representation of the 3D points
such that it reflects the grouping hierarchy and tag data. The main challenge is
that the data is noisy and highly variable. To this end, we present a tree-aware
metric-learning approach and demonstrate that such learned embeddings offer
excellent transfer to semantic segmentation tasks, especially when training data
is limited. Our approach reduces the relative error by 10.2% with 8 training
examples, by 11.72% with 120 training examples on the ShapeNet semantic
segmentation benchmark, in comparison to the network trained from scratch. By
utilizing tag data the relative error is reduced by 12.8% with 8 training
examples, in comparison to the network trained from scratch. These improvements
come at no additional labeling cost as the meta data is freely available.
Cite
@INPROCEEDINGS{8885650,
author={G. {Sharma} and E. {Kalogerakis} and S. {Maji}},
booktitle={2019 International Conference on 3D Vision (3DV)},
title={Learning Point Embeddings from Shape Repositories for Few-Shot
Segmentation},
year={2019},
volume={},
number={},
pages={67-75},}
|